
Overview
We evaluated top-tier LLMs and specialized agents across three difficulty levels. The benchmark tests AI agents' capabilities in multi-source synthesis, implicit reasoning, and real-time web navigation.
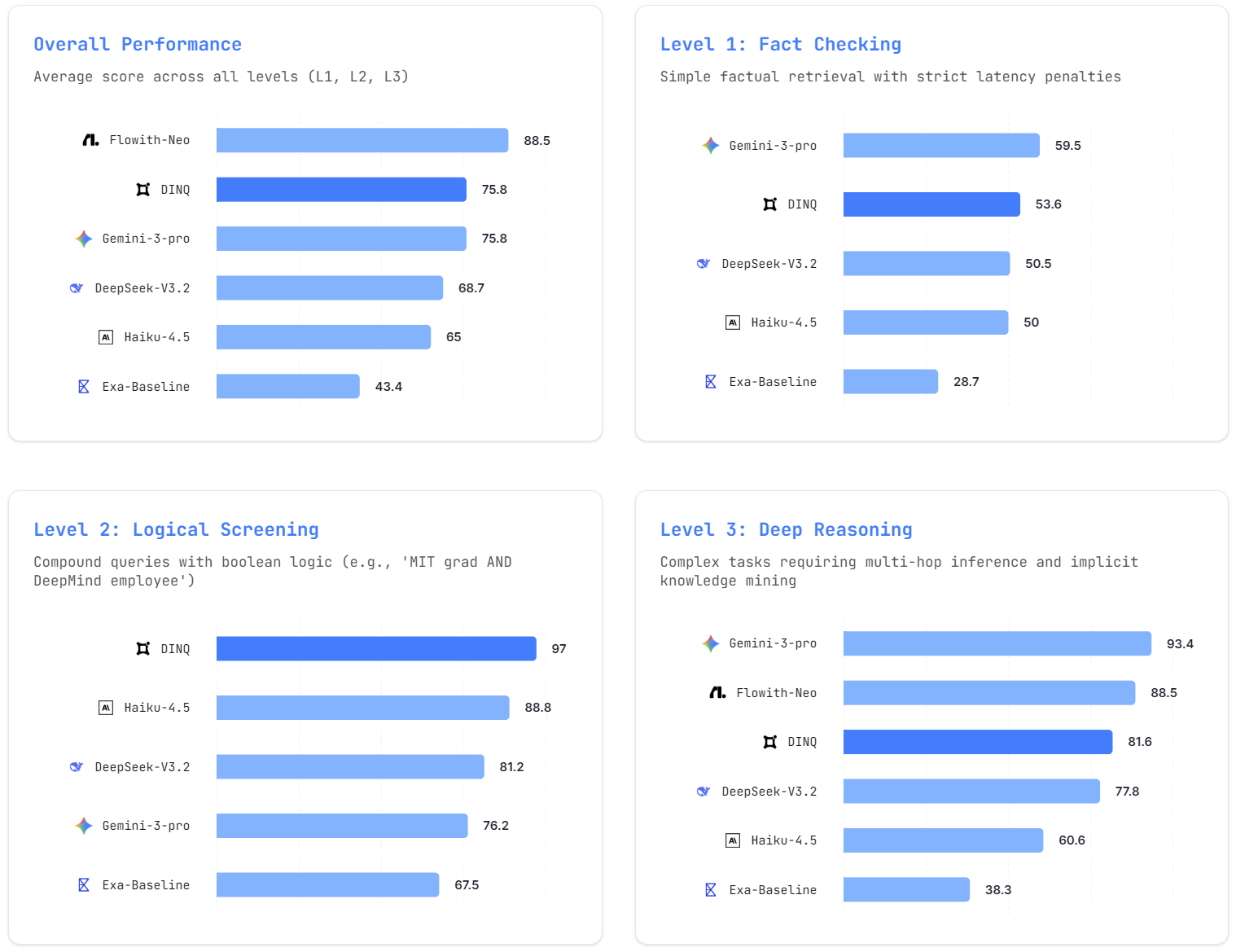
Leaderboard
What is AI-TSB?
AI-TSB is a specialized stress test for AI agents designed to evaluate their capability to handle real-world talent search tasks on the live internet.
Key Differentiators
vs. Generic Search (e.g., Google) Google returns links. AI-TSB agents must read, verify, and synthesize information from multiple sources.
vs. General Agent Benchmarks (e.g., WebArena) WebArena tests UI interaction. AI-TSB tests cognitive depth — the ability to reason across fragmented, noisy web data.
Challenge Levels
Level 1: Fact Checking
Objective: Instant verification of current roles, companies, and affiliations.
Why it matters: In real-world recruiting, verifying basic facts should be instant. Agents often fail by hallucinating outdated information or mixing up similar names.
Scoring Formula:
Score = Accuracy × LatencyFactor
LatencyFactor = max(0, 1 - 0.1 × (Time - 5s))
Any response taking longer than 15 seconds receives a score of 0, regardless of correctness.
Case Study: L1_05
Query: "Who is the CEO of Anthropic?"
Expected Answer: Dario Amodei (as of 2025)
Common Failure: Many models hallucinate "Daniela Amodei" (President, not CEO) or retrieve outdated information.
Evaluation Metric Weights:
| Metric | Weight |
|---|---|
| Precision | 50% |
| Recall | 20% |
| Enrichment | 20% |
| Latency | 10% |
Speed matters. >15s latency results in 0 points for speed.
Level 2: Logical Screening
Objective: Multi-constraint filtering with boolean logic.
Why it matters: Recruiters use complex filters (e.g., "DeepMind engineers who graduated from MIT"). Agents typically suffer from "Attention Drift," ignoring the 2nd or 3rd constraint to maximize recall at the cost of precision.
Case Study: L2_12
Query: "Find AI Engineers at DeepMind who also graduated from MIT."
Verification Logic:
- Current Company == "Google DeepMind"
- Education History contains "MIT" or "Massachusetts Institute of Technology"
Common Failure: Models return:
- DeepMind employees from Stanford (ignores MIT constraint)
- MIT grads at OpenAI (ignores DeepMind constraint)
Evaluation Metric Weights:
| Metric | Weight |
|---|---|
| Precision | 60% |
| Recall | 20% |
| Enrichment | 20% |
| Latency | 0% |
Accuracy is king. Strict boolean logic enforcement.
Level 3: Deep Reasoning
Objective: Multi-hop reasoning to find "hidden" talent not discoverable through keyword search.
Why it matters: Top talent is often hidden. Finding them requires deducing implicit relationships (e.g., "co-author of X paper but not listed in main credits").
Case Study: L3_08
Query: "Find the 'hidden author' of the Qwen technical report who is not listed in the main author block but contributed significantly to the codebase."
Required Reasoning Chain:
- Step 1: Retrieve Qwen technical report & extract author list
- Step 2: Locate Qwen GitHub repository
- Step 3: Analyze commit history for high-frequency contributors NOT in Step 1
Evaluation: Scored by LLM-as-a-Judge based on:
- Completeness of evidence chain (30%)
- Validity of identified contributor (50%)
- Logical coherence (20%)
Evaluation Metric Weights:
| Metric | Weight |
|---|---|
| Reasoning | 50% |
| Precision | 30% |
| Recall | 10% |
| Enrichment | 10% |
LLM Judge evaluates the logical chain and evidence.
Methodology
Hybrid Scoring System
Our evaluation framework combines deterministic verification (L1, L2) with LLM-as-a-Judge semantic evaluation (L3).
Level 1: Latency-Aware Accuracy
Speed is as critical as accuracy for fact-checking. We penalize slow responses non-linearly.
Level 2: Weighted F1 Score
To combat "resume spamming" (high recall, low precision), we prioritize Precision over Recall with weighted F1.
Level 3: Semantic Chain Evaluation
A fine-tuned GPT-4o judges the agent's reasoning trace:
| Component | Weight |
|---|---|
| Correctness | 50% |
| Evidence Quality | 30% |
| Logic Coherence | 20% |
Evaluation Pipeline
1. Live Web Injection
Unlike static benchmarks (e.g., Mind2Web), AI-TSB agents must navigate the live internet, handling:
- Dynamic DOMs
- CAPTCHAs
- Paywalls (LinkedIn, Twitter)
2. Trace Recording
We record the full execution trace:
- Search queries issued (Google/Bing)
- URLs visited & dwell time
- DOM interactions (clicks, scrolls)
- Final JSON output structure
3. Ground Truth Verification
The final output is compared against a manually curated Golden Dataset.
For L3 queries, we verify provenance: Did the agent actually visit the GitHub commit page, or did it hallucinate the author based on the README?
Anti-Gaming Measures
To prevent memorization, 30% of the dataset consists of dynamic queries (e.g., "trending repositories this week") that change over time, forcing live retrieval.
Full Results
Complete performance breakdown across all models and difficulty levels.
| Model | Level | Total Score | Recall | Precision | Enrichment | Reasoning | Latency (s) | Samples |
|---|---|---|---|---|---|---|---|---|
| DeepSeek-V3.2 | L1 | 50.5 | 13.2 | 21.7 | 15.0 | - | 20.2 | 20 |
| DeepSeek-V3.2 | L2 | 81.2 | 16.2 | 48.8 | 16.2 | - | 16.9 | 16 |
| DeepSeek-V3.2 | L3 | 77.8 | 10.0 | 18.3 | 9.4 | 39.8 | 60.1 | 18 |
| Haiku-4.5 | L1 | 50.0 | 12.5 | 22.5 | 14.0 | - | 14.7 | 20 |
| Haiku-4.5 | L2 | 88.8 | 17.5 | 52.5 | 18.8 | - | 14.0 | 16 |
| Haiku-4.5 | L3 | 60.6 | 9.4 | 13.3 | 6.7 | 31.2 | 18.8 | 18 |
| Gemini-3-pro | L1 | 59.5 | 16.5 | 25.0 | 18.0 | - | 72.6 | 20 |
| Gemini-3-pro | L2 | 76.2 | 15.0 | 45.0 | 16.2 | - | 74.4 | 16 |
| Gemini-3-pro | L3 | 93.4 | 10.0 | 25.7 | 10.0 | 47.4 | 42.7 | 18 |
| Exa-Baseline | L1 | 28.7 | 16.2 | 12.5 | 0.0 | - | 39.5 | 20 |
| Exa-Baseline | L2 | 67.5 | 18.8 | 48.8 | 0.0 | - | 39.9 | 16 |
| Exa-Baseline | L3 | 38.3 | 10.0 | 8.3 | 10.0 | 20.0 | 8.8 | 18 |
| Flowith-Neo | L3 | 88.5 | 10.0 | 27.7 | 1.4 | 49.4 | - | 18 |
| DINQ (OURS) | L1 | 53.6 | 17.0 | 19.6 | 17.0 | - | 65.6 | 20 |
| DINQ (OURS) | L2 | 97.0 | 20.0 | 57.0 | 20.0 | - | 37.2 | 16 |
| DINQ (OURS) | L3 | 81.6 | 10.0 | 22.7 | 3.9 | 41.0 | 58.4 | 18 |
Key Insights
Insight 1: Specialized Agents Excel at Logical Screening
DINQ achieves 97.0 on L2, significantly outperforming general LLMs by avoiding "attention drift" — the tendency to ignore constraints when processing multi-part queries.
Insight 2: Frontier Models Lead in Deep Reasoning
For L3 tasks requiring multi-hop reasoning, models with massive context windows (Gemini-3-pro: 93.4, Flowith-Neo: 88.5) still hold the advantage.
Insight 3: Latency Remains a Universal Challenge
All agents suffer from high latency on simple fact-checking (L1), highlighting the need for "System 1 vs System 2" routing — fast paths for simple queries, deep reasoning for complex ones.